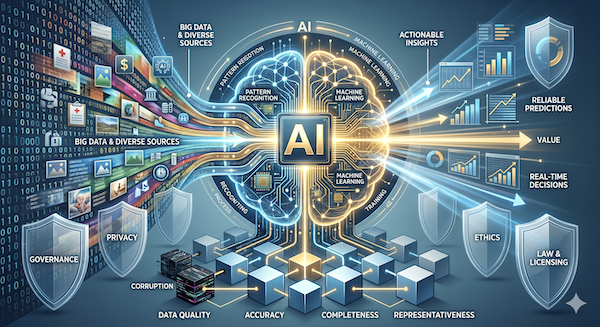
The relationship between Artificial Intelligence (AI) and data is fundamental and inseparable. You can think of data as the fuel that powers the AI engine. Without high-quality, relevant data, even the most sophisticated AI algorithms are useless. Conversely, AI provides the powerful tools needed to extract meaningful insights and value from the massive, complex datasets that define our modern world.
Here's a breakdown of the importance of this relationship across several key areas:
1. Data: The Foundation and Fuel for AI
AI, particularly machine learning (ML), does not "think" from scratch. It learns. This learning process is entirely dependent on data.
-
Learning Patterns and Relationships: ML algorithms are fed massive amounts of data to identify patterns, correlations, and dependencies. For example, a fraud detection AI learns what typical transactions look like by analyzing millions of legitimate ones. It can then identify unusual patterns that suggest fraud in new transactions.
-
Training and Development: Data is required at every stage of the AI lifecycle:
-
Training Data: The primary dataset used to "teach" the model. Its quantity and quality directly impact how well the model learns.
-
Validation Data: Used to tune the model's parameters during development and prevent it from simply memorizing the training data.
-
Test Data: A completely separate dataset used to evaluate the final model's performance and accuracy on unseen information.
-
Generalization: A good AI model isn't just accurate on its training data; it can generalize its learnings to make correct predictions on entirely new, similar data. A diverse and representative training dataset is crucial for good generalization.
2. The Vital Role of Data Quality
The famous computing adage "garbage in, garbage out" is especially true for AI. The quality of your data dictates the maximum potential of your AI. Poor data quality is one of the single biggest reasons AI projects fail.
- Accuracy: Are the data values correct? Incorrect labels in an image dataset will confuse an object recognition model.
- Completeness: Are there missing fields or variables? Missing data can obscure critical information and lead to unreliable models.
- Consistency: Is the data formatted uniformly across all sources? Inconsistent date formats or duplicate customer records can skew analysis.
- Diversity and Representativeness: Does the data reflect the real world the AI will operate in? A facial recognition system trained only on one demographic will perform poorly on others, leading to harmful bias. For example, medical diagnosis AI must be trained on diverse patient populations to avoid inaccurate or biased outcomes for certain groups.
3. The Big Data Connection
The recent boom in AI has been fueled by the explosion of Big Data. AI thrives on the "three V's" of Big Data:
-
Volume: Large-scale datasets are needed to train complex models, like the deep neural networks that power self-driving cars or advanced natural language understanding.
-
Variety: AI can process all types of data:
-
Structured Data: Organized data found in spreadsheets and databases (e.g., customer records, financial transactions).
-
Unstructured Data: Messy, real-world data like images, video, text documents, audio recordings, and sensor data.
-
Velocity: Modern AI systems need to process and act on data in real-time, such as in high-frequency trading or to detect security threats the moment they occur.
4. Critical Data Ownership, Ethics, and Governance
The heavy reliance on data introduces complex and critical non-technical challenges.
- Ethics and Bias: As mentioned, biased data will almost inevitably lead to biased AI decisions, which can have significant ethical and social implications in areas like hiring, lending, and law enforcement.
- Privacy and Regulation: Using data, especially personal information, requires strict adherence to privacy laws like the General Data Protection Regulation (GDPR) in Europe. These regulations dictate how data can be collected, stored, used, and who it can be shared with.
- Ownership and Licensing: Just because data is online doesn't mean it's free to use for AI training. Complex questions surround who owns data generated by users, sensors, or machines. Using unlicensed or copyrighted data can lead to serious legal risks and litigation, as seen in high-profile lawsuits where artists and companies have sued AI firms for training on their work without permission.
Summary
In essence, AI and data are two sides of the same coin. AI provides the intelligence to make sense of data at scale, while data provides the essential knowledge and experience that makes AI smart. This symbiotic relationship is the driving force behind current and future innovations across nearly every industry, from personalized medicine to autonomous transport.