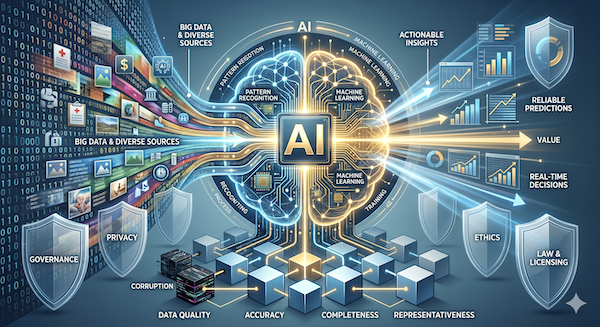
إن العلاقة بين الذكاء الاصطناعي (Artificial Intelligence - AI) والبيانات هي علاقة جوهرية ولا تقبل الانفصال. يمكنك التفكير في البيانات كأنها الوقود الذي يحرك محرك الذكاء الاصطناعي. فمن دون بيانات عالية الجودة وذات صلة، فإن أكثر خوارزميات (algorithms) الذكاء الاصطناعي تطوراً ستكون عديمة الفائدة. وعلى العكس من ذلك، يوفر الذكاء الاصطناعي الأدوات القوية اللازمة لاستخلاص رؤى وقيمة ذات مغزى من مجموعات البيانات الهائلة والمعقدة التي تميز عالمنا الحديث.
وفيما يلي تفصيل لأهمية هذه العلاقة عبر عدة مجالات رئيسية:
1. البيانات: الأساس والوقود للذكاء الاصطناعي
إن الذكاء الاصطناعي، وخاصة تعلم الآلة (Machine Learning - ML)، لا "يفكر" من تلقاء نفسه ومن نقطة الصفر، بل هو يتعلم. وتعتمد عملية التعلم هذه كلياً على البيانات.
-
تعلم الأنماط والعلاقات: يتم تزويد خوارزميات تعلم الآلة بكميات هائلة من البيانات لتحديد الأنماط، والارتباطات، والاعتماديات. على سبيل المثال، يتعلم الذكاء الاصطناعي الخاص بكشف الاحتيال شكل المعاملات النموذجية من خلال تحليل الملايين من المعاملات المشروعة، ليمكنه بعد ذلك تحديد الأنماط غير العادية التي تشير إلى وجود احتيال في المعاملات الجديدة.
-
التدريب والتطوير: البيانات مطلوبة في كل مرحلة من دورة حياة الذكاء الاصطناعي:
-
بيانات التدريب (Training Data): مجموعة البيانات الأساسية المستخدمة لـ "تعليم" النموذج. وتؤثر كميتها وجودتها بشكل مباشر على مدى جودة تعلم النموذج.
-
بيانات التحقق (Validation Data): تُستخدم لضبط معلمات النموذج أثناء التطوير ومنعه من مجرد حفظ بيانات التدريب.
-
بيانات الاختبار (Test Data): مجموعة بيانات منفصلة تماماً تُستخدم لتقييم أداء النموذج النهائي ودقته على معلومات لم يسبق له رؤيتها.
-
التعميم (Generalization): لا تقتصر جودة نموذج الذكاء الاصطناعي على دقته في بيانات التدريب الخاصة به فحسب، بل في قدرته على تعميم ما تعلمه لاتخاذ تنبؤات صحيحة بناءً على بيانات جديدة تماماً ومشابهة لها. ويعد الحصول على مجموعة بيانات تدريب متنوعة وممثلة أمراً بالغ الأهمية لضمان التعميم الجيد.
2. الدور الحيوي لجودة البيانات
إن المثل الشهير في مجال الحوسبة "إذا أدخلت قمامة، فستخرج قمامة" (garbage in, garbage out) ينطبق بشكل خاص على الذكاء الاصطناعي. وتحدد جودة بياناتك الحد الأقصى لإمكانات الذكاء الاصطناعي لديك. وتعد رداءة جودة البيانات أحد أهم الأسباب المنفردة لفشل مشاريع الذكاء الاصطناعي.
- الدقة: هل قيم البيانات صحيحة؟ إن التصنيفات غير الصحيحة في مجموعة بيانات الصور ستؤدي إلى إرباك نموذج التعرف على الأشياء.
- الشمولية: هل هناك حقول أو متغيرات مفقودة؟ يمكن للبيانات المفقودة أن تحجب معلومات حيوية وتؤدي إلى نماذج غير موثوقة.
- الاتساق: هل تم تنسيق البيانات بشكل موحد عبر جميع المصادر؟ إن تنسيقات التاريخ غير المتسقة أو سجلات العملاء المكررة يمكن أن تؤدي إلى تحريف التحليل.
- التنوع والتمثيل: هل تعكس البيانات العالم الحقيقي الذي سيعمل فيه الذكاء الاصطناعي؟ إن نظام التعرف على الوجه الذي تم تدريبه على ديموغرافية واحدة فقط سيؤدي أداءً ضعيفاً مع الديموغرافية الأخرى، مما يؤدي إلى تحيز (Bias) ضار. على سبيل المثال، يجب تدريب الذكاء الاصطناعي للتشخيص الطبي على مجموعات متنوعة من المرضى لتجنب نتائج غير دقيقة أو منحازة لمجموعات معينة.
3. الارتباط بالبيانات الضخمة (Big Data)
إن الازدهار الأخير في الذكاء الاصطناعي كان وقوده الانفجار في البيانات الضخمة (Big Data). يزدهر الذكاء الاصطناعي بالاعتماد على "العناصر الثلاثة التي تبدأ بحرف V" للبيانات الضخمة:
-
الحجم (Volume): هناك حاجة إلى مجموعات بيانات واسعة النطاق لتدريب النماذج المعقدة، مثل الشبكات العصبية العميقة التي تشغل السيارات ذاتية القيادة أو الفهم المتقدم للغة الطبيعية.
-
التنوع (Variety): يمكن للذكاء الاصطناعي معالجة جميع أنواع البيانات:
-
البيانات المهيكلة (Structured Data): البيانات المنظمة الموجودة في الجداول وقواعد البيانات (مثل سجلات العملاء، والمعاملات المالية).
-
البيانات غير المهيكلة (Unstructured Data): البيانات الفوضوية الواقعية مثل الصور، ومقاطع الفيديو، والمستندات النصية، والتسجيلات الصوتية، وبيانات الاستشعار.
-
السرعة (Velocity): تحتاج أنظمة الذكاء الاصطناعي الحديثة إلى معالجة البيانات واتخاذ إجراءات بناءً عليها في الوقت الفعلي (real-time)، مثل التداول عالي التكرار أو اكتشاف التهديدات الأمنية في لحظة وقوعها.
4. ملكية البيانات والأخلاقيات والحوكمة الحاسمة
إن الاعتماد الكبير على البيانات يطرح تحديات غير تقنية معقدة وحاسمة.
- الأخلاقيات والتحيز: كما ذكرنا، ستؤدي البيانات المنحازة حتماً إلى قرارات غير عادلة من الذكاء الاصطناعي، مما يمكن أن يكون له آثار أخلاقية واجتماعية كبيرة في مجالات مثل التوظيف، والإقراض، وإنفاذ القانون.
- الخصوصية واللوائح: إن استخدام البيانات، وخاصة المعلومات الشخصية، يتطلب التزاماً صارماً بقوانين الخصوصية مثل اللائحة العامة لحماية البيانات (General Data Protection Regulation - GDPR) في أوروبا. وتحدد هذه اللوائح كيفية جمع البيانات، وتخزينها، واستخدامها، ومع من يمكن مشاركتها.
- الملكية والترخيص: مجرد وجود البيانات على الإنترنت لا يعني أنها مجانية للاستخدام لتدريب الذكاء الاصطناعي. تحيط أسئلة معقدة بمن يملك البيانات التي يولدها المستخدمون، أو أجهزة الاستشعار، أو الآلات. يمكن أن يؤدي استخدام بيانات غير مرخصة أو محمية بحقوق الطبع والنشر (copyright) إلى مخاطر قانونية ودعاوى قضائية خطيرة، كما رأينا في الدعاوى القضائية رفيعة المستوى حيث قام فنانون وشركات بمقاضاة شركات الذكاء الاصطناعي للتدريب على أعمالهم دون إذن.
ملخص
في الجوهر، الذكاء الاصطناعي والبيانات هما وجهان لعملة واحدة. الذكاء الاصطناعي يوفر الذكاء لفهم البيانات على نطاق واسع، بينما توفر البيانات المعرفة والخبرة الأساسية التي تجعل الذكاء الاصطناعي ذكياً. هذه العلاقة التكافلية هي القوة الدافعة وراء الابتكارات الحالية والمستقبلية في جميع الصناعات تقريباً، من الطب الشخصي إلى النقل الذاتي القيادة.